Raspberry PI 4B Network Performance #
This article discusses the network performance of the built-in ethernet controller of the Raspberry Pi 4B.
I ran all measurements on Alpine Linux 3.15 and a 5.15.4-0-rpi4 aarch64 kernel. My measurement tool of choice was iperf3.
As a communication partner, I used a Windows 10 PC on which I stopped all other network services and disconnected LAN/Internet to allow for undisturbed measurements.
Half-duplex #
When one machine is sending, and the other one is receiving data (half-duplex), the built-in ethernet controller can almost fully saturate the 1Gbit/s line. With a network layer MTU of 1500 bytes the theoretical max throughput is ~949Mbit/s:
- 1500bytes Ethernet payload - 40bytes TCP/IP header = 1460bytes (payload available to iperf)
- 1500bytes + 26bytes + 12bytes layer 1 and 2 frame = 1538bytes (on phy medium per frame)
- net / gross: 1460bytes / 1538bytes = 0.9493% of link speed
Setup:
- Windows 10 i5 4 Core PC with IP:
10.0.0.100 - RPI4B 8GB with IP:
10.0.0.1 - 10 parallel TCP streams
- One test run is 60 seconds
- 5 seconds warm-up time
PC sending #
iperf3.exe -c 10.0.0.1 -t 65 -O 5 -P 10
(CPU Affinity manually set to CPU 3 and 4)

[ ID] Interval Transfer Bandwidth
[ 4] 0.00-64.99 sec 737 MBytes 95.1 Mbits/sec sender
[ 6] 0.00-64.99 sec 737 MBytes 95.1 Mbits/sec sender
[ 8] 0.00-64.99 sec 736 MBytes 95.0 Mbits/sec sender
[ 10] 0.00-64.99 sec 736 MBytes 95.0 Mbits/sec sender
[ 12] 0.00-64.99 sec 736 MBytes 94.9 Mbits/sec sender
[ 14] 0.00-64.99 sec 736 MBytes 94.9 Mbits/sec sender
[ 16] 0.00-64.99 sec 735 MBytes 94.9 Mbits/sec sender
[ 18] 0.00-64.99 sec 735 MBytes 94.9 Mbits/sec sender
[ 20] 0.00-64.99 sec 734 MBytes 94.8 Mbits/sec sender
[ 22] 0.00-64.99 sec 733 MBytes 94.6 Mbits/sec sender
[SUM] 0.00-64.99 sec 7.18 GBytes 949 Mbits/sec sender
Raspberry PI4 sending #
iperf3.exe -c 10.0.0.100 -t 65 -O 5 -P 10 -i 60 -A 3 -Z
- The
Zoption enables the “zero-copy” optimization - The
A 3option runs iperf on the 4th CPU to ensure CPUs are equally used
From the perspective of the Windows 10 machine:

iperf3 output on the Raspberry PI4:
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-65.00 sec 559 MBytes 72.1 Mbits/sec 0 sender
[ 7] 0.00-65.00 sec 548 MBytes 70.8 Mbits/sec 0 sender
[ 9] 0.00-65.00 sec 648 MBytes 83.6 Mbits/sec 0 sender
[ 11] 0.00-65.00 sec 821 MBytes 106 Mbits/sec 0 sender
[ 13] 0.00-65.00 sec 570 MBytes 73.6 Mbits/sec 0 sender
[ 15] 0.00-65.00 sec 1.03 GBytes 136 Mbits/sec 0 sender
[ 17] 0.00-65.00 sec 822 MBytes 106 Mbits/sec 0 sender
[ 19] 0.00-65.00 sec 1.29 GBytes 171 Mbits/sec 0 sender
[ 21] 0.00-65.00 sec 190 MBytes 24.5 Mbits/sec 0 sender
[ 23] 0.00-65.00 sec 826 MBytes 107 Mbits/sec 0 sender
[SUM] 0.00-65.00 sec 7.19 GBytes 950 Mbits/sec 0 sender
Full-duplex #
When both machines send and receive simultaneously, the throughput drops significantly to about ~550Mbits/sec for both sides.

Windows sender:
[ ID] Interval Transfer Bandwidth
[ 4] 0.00-64.99 sec 407 MBytes 52.6 Mbits/sec sender
[ 6] 0.00-64.99 sec 481 MBytes 62.1 Mbits/sec sender
[ 8] 0.00-64.99 sec 518 MBytes 66.8 Mbits/sec sender
[ 10] 0.00-64.99 sec 394 MBytes 50.9 Mbits/sec sender
[ 12] 0.00-64.99 sec 211 MBytes 27.2 Mbits/sec sender
[ 14] 0.00-64.99 sec 315 MBytes 40.7 Mbits/sec sender
[ 16] 0.00-64.99 sec 434 MBytes 56.0 Mbits/sec sender
[ 18] 0.00-64.99 sec 487 MBytes 62.9 Mbits/sec sender
[ 20] 0.00-64.99 sec 301 MBytes 38.8 Mbits/sec sender
[ 22] 0.00-64.99 sec 632 MBytes 81.6 Mbits/sec sender
[SUM] 0.00-64.99 sec 4.08 GBytes 540 Mbits/sec sender
Raspberry PI sender:
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-65.00 sec 85.9 MBytes 11.1 Mbits/sec 0 sender
[ 7] 0.00-65.00 sec 89.4 MBytes 11.5 Mbits/sec 0 sender
[ 9] 0.00-65.00 sec 410 MBytes 53.0 Mbits/sec 0 sender
[ 11] 0.00-65.00 sec 982 MBytes 127 Mbits/sec 0 sender
[ 13] 0.00-65.00 sec 90.0 MBytes 11.6 Mbits/sec 0 sender
[ 15] 0.00-65.00 sec 91.7 MBytes 11.8 Mbits/sec 0 sender
[ 17] 0.00-65.00 sec 87.8 MBytes 11.3 Mbits/sec 0 sender
[ 19] 0.00-65.00 sec 421 MBytes 54.3 Mbits/sec 0 sender
[ 21] 0.00-65.00 sec 985 MBytes 127 Mbits/sec 0 sender
[ 23] 0.00-65.00 sec 984 MBytes 127 Mbits/sec 0 sender
[SUM] 0.00-65.00 sec 4.13 GBytes 545 Mbits/sec 0 sender
Performance Optimization 1 - Interrupt CPU Affinity #
The following shows the interrupt distribution over the 4 CPUs on the Raspberry PI4:
lbox:~# cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
9: 0 0 0 0 GICv2 25 Level vgic
11: 59242 6754 27139 15696 GICv2 30 Level arch_timer
12: 0 0 0 0 GICv2 27 Level kvm guest vtimer
18: 860 0 0 0 GICv2 65 Level fe00b880.mailbox
22: 0 0 0 0 GICv2 112 Level bcm2708_fb DMA
24: 347 0 0 0 GICv2 114 Level DMA IRQ
31: 55 0 0 0 GICv2 66 Level VCHIQ doorbell
32: 7045 0 0 0 GICv2 158 Level mmc1, mmc0
33: 0 0 0 0 GICv2 48 Level arm-pmu
34: 0 0 0 0 GICv2 49 Level arm-pmu
35: 0 0 0 0 GICv2 50 Level arm-pmu
36: 0 0 0 0 GICv2 51 Level arm-pmu
38: 1899524 0 0 0 GICv2 189 Level eth0
39: 214360 0 0 0 GICv2 190 Level eth0
46: 364 0 0 0 BRCM STB PCIe MSI 524288 Edge xhci_hcd
Interrupt 38 is responsible for sending and interrupt 39 for receiving data. These interrupts are only processed by CPU0, which is not ideal.
Thus, for the first performance optimization, I made the following changes:
- Pin the interrupt which signals a send operation has finished to CPU 1 (counting from 0)
- Pin the interrupt which signals data has been received to CPU 2
echo 2 > /proc/irq/38/smp_affinity
echo 4 > /proc/irq/39/smp_affinity
Note: The RPI4 ARM GICv2 cannot signal one particular interrupt to more than one CPU. For example, setting the affinity mask for IRQ 38 to 6 will still lead to CPU 1 processing all interrupts.
After another full-duplex run, the interrupt stats showed a much better distribution over CPU 1 and 2:
38: 1899524 107186 0 0 GICv2 189 Level eth0
39: 214360 0 398379 0 GICv2 190 Level eth0
The Raspberry PI was almost back to its half-duplex sending speed, whereas the Windows PC 10 send-performance (Raspberry PI receive performance) did not increase quite as much and also, the throughput fluctuated much more:
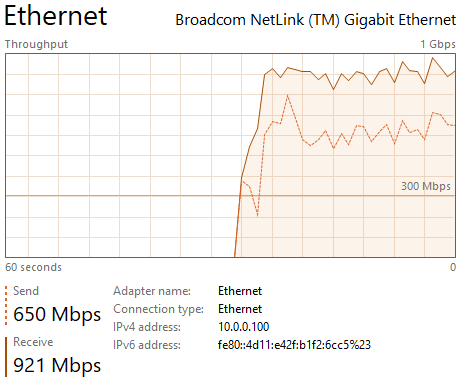
Windows Sender:
[SUM] 0.00-64.99 sec 4.64 GBytes 613 Mbits/sec sender
Raspberry PI Sender:
[SUM] 0.00-65.00 sec 6.54 GBytes 864 Mbits/sec 315 sender
Note: The Raspberry PI stats show 315 TCP retransmissions.
Performance Optimization 2 - Paket Steering #
So far, I have looked at hardware interrupts signalled when data has been received on the link layer. However, the kernel also needs to execute code that handles further data processing (Layer 3 and above). For instance, it needs to decide whether a packet is dropped, forwarded to another interface or sent to a local process.
The following commands enable all CPUs for the kernel code which handles the receive and transmit queues:
echo f >/sys/class/net/eth0/queues/tx-0/xps_cpus
echo f >/sys/class/net/eth0/queues/tx-1/xps_cpus
echo f >/sys/class/net/eth0/queues/tx-2/xps_cpus
echo f >/sys/class/net/eth0/queues/tx-3/xps_cpus
echo f >/sys/class/net/eth0/queues/tx-4/xps_cpus
echo f >/sys/class/net/eth0/queues/rx-0/rps_cpus
Note: Some more insights about the way this works can be found here
This brings another performance gain and removes the throughput fluctuation seen before:
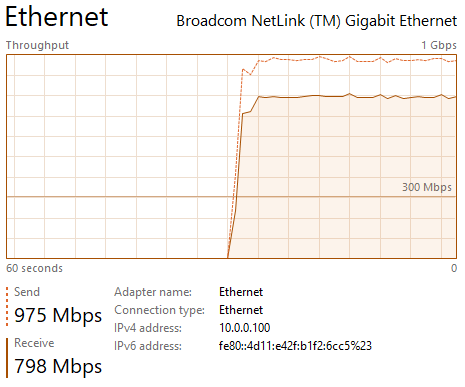
Windows Sender:
[SUM] 0.00-64.99 sec 7.08 GBytes 935 Mbits/sec sender
Raspberry PI Sender:
[SUM] 0.00-65.00 sec 5.78 GBytes 764 Mbits/sec 0 sender
Performance increased on both machines, with the Windows machine sending again at almost line speed.
Looking at top, the interrupt controller seems to be at peak processing capacity in regards to the send queue:
Mem: 97216K used, 7903080K free, 120K shrd, 3384K buff, 21636K cached
CPU0: 0% usr 0% sys 0% nic 98% idle 0% io 0% irq 0% sirq
CPU1: 0% usr 0% sys 0% nic 0% idle 0% io 0% irq 100% sirq
CPU2: 0% usr 0% sys 0% nic 74% idle 0% io 0% irq 24% sirq
CPU3: 3% usr 62% sys 0% nic 30% idle 0% io 0% irq 3% sirq
Load average: 0.57 0.15 0.04 6/114 2240
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
17 2 root RW 0 0% 1 28% [ksoftirqd/1]
2231 2228 root S 2332 0% 3 14% iperf3 -s
2240 2186 root R 2304 0% 3 5% iperf3 -c 10.0.0.100 -t 65 -O 5 -P 10 -i 60 -A 3 -Z
22 2 root RW 0 0% 2 5% [ksoftirqd/2]
2239 2236 root R 1668 0% 0 0% top
7 2 root IW 0 0% 2 0% [kworker/u8:0-ev]
38 2 root IW 0 0% 0 0% [kworker/0:2-eve]
11 2 root SW 0 0% 0 0% [ksoftirqd/0]
Performance Optimization Attempt - Overclocking the CPU #
I added the following settings to the according usercfg.txt section:
over_voltage=6
arm_freq=2000
force_turbo=1
and verified that the CPU speed is indeed at 2Ghz by running vcgencmd measure_clock arm. (Please note that force_turbo=1 enforces these settings
even when the CPU is idle and should not be used under normal circumstances)
Increasing the CPU speed showed a negligible improvement with the Raspberry PI send-performance changing from 764 to 773 Mbits/sec.

This article goes into great detail about overclocking the PI4.
Performance Optimization Attempt - PCIe Payload Setting #
Inspired by
this comment (coming from Jeff Geerling’s post
here), I added
pci=pcie_bus_perf to the kernel parameters in cmdline.txt and the effect of this kernel parameter can be verified by executing lspci -vv:
lbox:~# lspci -vv
00:00.0 PCI bridge: Broadcom Inc. and subsidiaries BCM2711 PCIe Bridge (rev 10) (prog-if 00 [Normal decode])
Device tree node: /sys/firmware/devicetree/base/scb/pcie@7d500000/pci@0,0
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx-
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0
Interrupt: pin A routed to IRQ 0
Bus: primary=00, secondary=01, subordinate=01, sec-latency=0
I/O behind bridge: 00000000-00000fff [size=4K]
Memory behind bridge: c0000000-c00fffff [size=1M]
Prefetchable memory behind bridge: [disabled]
Secondary status: 66MHz- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- <SERR- <PERR-
BridgeCtl: Parity- SERR+ NoISA- VGA- VGA16- MAbort- >Reset- FastB2B-
PriDiscTmr- SecDiscTmr- DiscTmrStat- DiscTmrSERREn-
Capabilities: [48] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=1 PME-
Capabilities: [ac] Express (v2) Root Port (Slot-), MSI 00
DevCap: MaxPayload 512 bytes, PhantFunc 0
ExtTag- RBE+
DevCtl: CorrErr- NonFatalErr- FatalErr- UnsupReq-
RlxdOrd+ ExtTag- PhantFunc- AuxPwr+ NoSnoop+
MaxPayload 512 bytes, MaxReadReq 512 bytes
DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend-
LnkCap: Port #0, Speed 5GT/s, Width x1, ASPM L0s L1, Exit Latency L0s <1us, L1 <2us
ClockPM+ Surprise- LLActRep- BwNot+ ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 5GT/s (ok), Width x1 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt+ ABWMgmt+
...
01:00.0 USB controller: VIA Technologies, Inc. VL805/806 xHCI USB 3.0 Controller (rev 01) (prog-if 30 [XHCI])
Subsystem: VIA Technologies, Inc. VL805/806 xHCI USB 3.0 Controller
...
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s <64ns, L1 <1us
ExtTag- AttnBtn- AttnInd- PwrInd- RBE+ FLReset- SlotPowerLimit 0.000W
DevCtl: CorrErr- NonFatalErr- FatalErr- UnsupReq-
RlxdOrd+ ExtTag- PhantFunc- AuxPwr- NoSnoop+
MaxPayload 256 bytes, MaxReadReq 256 bytes
Under DevCap the tool shows the maximum payload supported by the PCI Bridge, respectively, the USB controller.
Under DevCtl you can find the current setting which are MaxPayload 512 bytes, MaxReadReq 512 bytes for the PCI Bridge and
MaxPayload 256 bytes, MaxReadReq 256 bytes for the USB controller.
(Details about the kernel parameter can be found here.)
With this change, I could not observe any further performance improvement. I assume that the PI4 ethernet controller is not sitting on the PCI bus but connected to the CPU via different means. However, changing the maximum payload size might affect external USB3 devices.
Summary #
After applying the interrupt tweaks described above, the Raspberry PI4B shows an impressive full-duplex throughput over 20 connections with a download speed of 936Mbit/s and an upload speed of 764Mbit/s.
Overclocking the CPU or increasing the PCI-express payload did not result in a higher upload speed. The output of top or atop suggest
the interrupt controller is at its peak processing capacity for the send queue with 95% and higher utilization.
It also needs to be considered that iperf itself requires CPU power and might limit throughput.
Finally, the Raspberry PI shows higher receive than send-performance in full-duplex in all scenarios.